
With the release of MalChela v3.0, I’m introducing features that shift the focus from tool-by-tool execution to a more structured investigative workflow. While the core philosophy of lightweight, file-first analysis remains unchanged, this version introduces smarter ways to manage investigations, track findings, and automate common analysis patterns, all with minimal fuss.
In this post, I’ll walk through the new Case Management system, the replacement of MismatchMiner with FileMiner, and the ability to identify and launch suggested tools — even in batch — based on file characteristics. These changes aim to reduce friction in multi-tool workflows and help analysts move faster without losing visibility or control.
Cases: A Lightweight Way to Stay Organized
Until now, MalChela has operated in an ephemeral mode. You selected a tool, pointed it at a file or folder, and reviewed the output. Any saved results would be grouped by tool, but without much context.
Cases change that. In v3.0, you can start a new case from a file or folder — and everything from that point forward is grouped under that case. Tool outputs are saved to a dedicated case folder, file hashes are tracked, and metadata is preserved for review or reanalysis.
You don’t need to create a case for every run — MalChela still supports standalone tool execution. But when you’re working with a malware sample set, an incident directory, or a disk image extract, cases give you the ability to:
- Save tool results in a consistent location
- Track analysis history per file
- Reopen previous sessions with full context
- Add notes, tags, and categorization (e.g., “suspicious”, “clean”, “needs review”)
Hello FileMiner: Goodbye MismatchMiner
The MismatchMiner tool was originally designed to surface anomalies between file names and actual content — a common trick in malicious attachments or script dropper chains. It worked well, but its scope was narrow.
FileMiner replaces it, expanding the logic to support full file-type classification and metadata inspection across an entire folder. It still flags mismatches, but now it also:
- Detects embedded file types using magic bytes
- Groups files by class (e.g., images, documents, executables, archives)
- Calculates hashes for correlation and NSRL comparison
- Extracts size, extension, and other key metadata
- Saves both a human-readable .txt summary and a structured .json report
The output is designed to be used both manually and programmatically — which brings us to one of v3.0’s most important additions: tool suggestions.
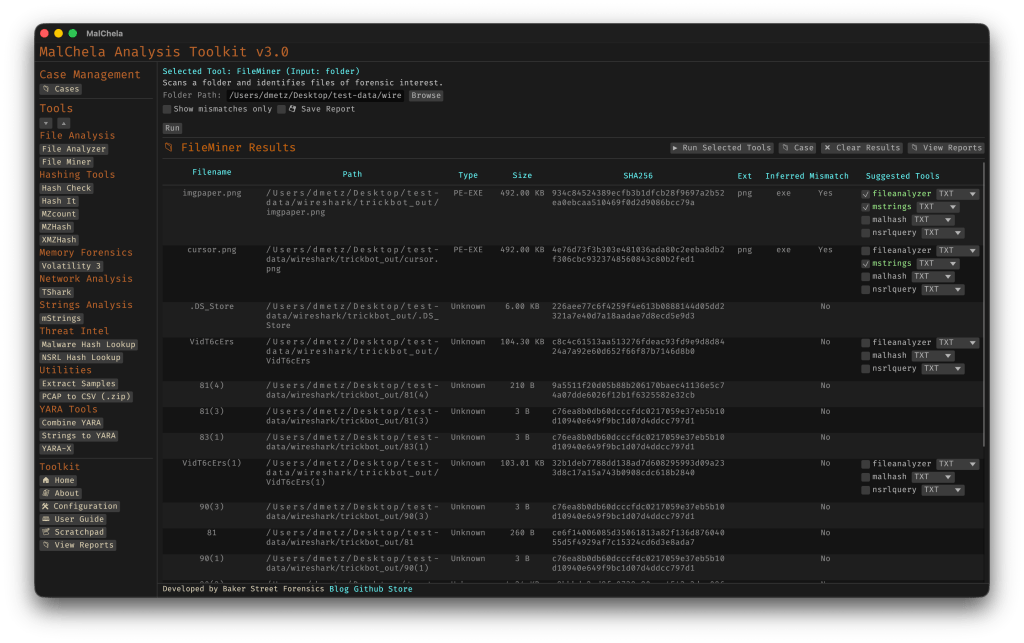
Suggested Tools and Batch Execution
Once FileMiner runs, it doesn’t just stop at reporting. Based on each file’s type and characteristics, it can now suggest one or more appropriate tools from the MalChela suite. These suggestions are surfaced right in the GUI — or in the CLI if you’re running FileMiner interactively. From there, you can choose to launch the recommended tool(s) on a per-file basis or queue up several for batch execution.
This makes it much faster to pivot from triage to deeper inspection. No more switching tools manually or copying paths. You stay within the flow — and more importantly, you reduce the risk of skipping important analysis steps.
CLI and GUI Improvements Aligned
These features are available in both the CLI and GUI editions of MalChela. In the CLI, FileMiner presents an interactive table of results. You can pick a file, see its suggested tools, and choose which one to run. When you’re done, you can return to the table and continue with the next file.
The GUI extends this even further, allowing you to:
- View and scroll through full case history
- Run tools with live output streaming
- Reopen previous FileMiner runs from saved reports
- Run all suggested tools on all files with one click (if desired)
These features let you treat MalChela more like a toolbox with memory, not just a launcher.
CLI Enhancements:
The command-line interface has also received a quiet but meaningful upgrade. Tool menus are now organized with clear numeric indexes and shortcodes, making it faster to navigate and launch tools without needing to retype full names. This small change goes a long way during repetitive tasks or when working in a time-constrained triage setting.
FileMiner supports an interactive loop: after running a tool on a selected file, you’re returned to the main results table — no need to restart the scan or re-navigate the menu. This allows you to run additional tools on different files within the same dataset, making FileMiner feel more like a lightweight control center for follow-up actions. It’s a subtle shift, but one that significantly reduces friction in batch-style or exploratory workflows.

Closing Thoughts
MalChela 3.0 reflects a steady evolution — not a revolution. It’s built on real-world feedback and a desire to make forensic and malware analysis a little less scattered. Whether you’re a one-person IR team or just trying to stay organized during a reverse engineering exercise, the new case features and smarter triage capabilities should save you time.
If you’ve been using MalChela already, I think this update will feel like a natural (and welcome) extension. And if you haven’t tried it yet, there’s never been a better time to start.
Download: https://github.com/dwmetz/MalChela/releases
User Guide: https://dwmetz.github.io/MalChela/

















